A few weeks ago I looked at a project by Luke McGregor (blog|twitter) that benchmarks a variety of ORMs doing common operations at the 1 to 10,000 record scales. I was curious to see how the ORMs he had included would fare against common ADO methods and how those ADO methods would compare to one another.
My Original Post: Evaluating ORMs for Batch Data Performance
Source Code: My fork of StaticVoid.OrmPerformance
I received a lot of good feedback and suggestions on that post, and implemented all of the additions (except Kermit's, oops). While I am still looking primarily at bulk insert performance, I also implemented the other test operations and Luke has pulled most of the changes back into his project (I am behind on issuing a pull request for NHibernate, sorry). This post is a follow-up on those additions with an updated conclusion, if you hadn't read the previous post, it's probably still worth a read.
The Updated Lineup
The updated lineup for tests now looks like:
- EntityFramework 4.1
- Basic Configuration (No optimizations)
- AutoDetectChanges Disabled
- Tuned
- EntityFramework 5.0 beta1
- Basic Configuration (No optimizations)
- AutoDetectChanges Disabled
- Proxy Entities
- Tuned
- Dapper 1.8
- Dapper Rainbow
- My Best effort at making it go fast
- Batching inserts/updates using transactions
- LINQ to SQL
- Basic Configuration (No optimizations)
- Tuned
- NHibernate 3.2.0.4
- Basic implementation
- Stateless + 200 record batches
- Stateless + 1000 record batches
- PetaPoco 3.04
- Basic implementation
- Batching inserts via transaction
- Simple.Data 1.0.0 rc 0
- Basic implementation
- Batch inserts (built-in, automagical)
- Raw ADO methods
- Basic SQL Command
- SQL Command w/ Transaction
- Bulk insert via SqlDataAdapter
- Bulk insert via SqlBulkCopy and SqlBulkCopy w/ Table Lock option
- Bulk insert via one really big SQL string (single insert w/ lots of concatenated value statements)
Along the way I also updated the project to include more information in failing assertions (the state is asserted after each test is run).
The Results
I was simultaneously surprised and not surprised at the results. With Mark Rendle (blog|twitter) suggesting I add Simple.Data, I fully expected it to keep up with SqlBulkCopy, but it was still surprising to see the real, raw data.
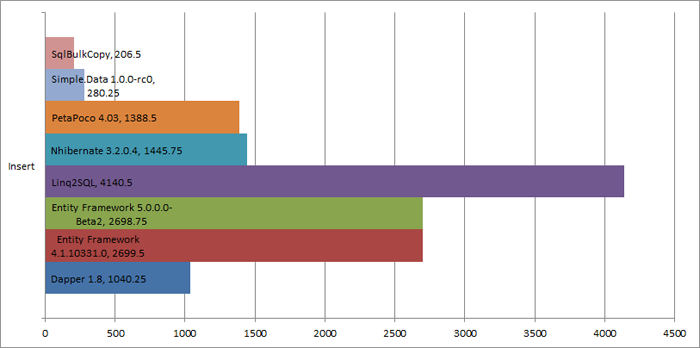
10,000 row inserts, Best times for each category
Raw SqlBulkCopy was still the best option for 10,000 records (this is the TabLock option variant), but Simple.Data was right up there with it. PetaPoco and NHibernate are our other new additions and they were fairly close, about 20-25% slower than Dapper, or about 7x the SqlBulkCopy test.
But the important item on this graph really is Simple.Data. There are many that argue that all ORMs are slow and not worth spending time on but this is clearly not so. Simple.Data was a little slower than SqlBulkCopy and much faster than the other raw ADO variants. And it does this with no column mappings, no tricks and no special configurations. That is a huge milestone for ORMs and makes it tempting to use instead of SqlBulkCopy, as this method may actually be less fragile (no column mappings have to be manually defined).
_db = Database.OpenConnection(connectionString.FormattedConnectionString);
_entitiesToInsert = new List<TestEntity>();
}
public void Add(TestEntity entity) {
_entitiesToInsert.Add(entity);
}
public void Commit() {
_db.TestEntities.Insert(_entitiesToInsert);
}
Create a connection, add as many items as you want to the list, then call Insert on the whole list. Magic.
More Detail
In the last post I included a comparison of all of the various methods used to insert data as a single graph. Unfortunately that graph was hard to read, as the basic Entity Framework methods were operating about an order of magnitude slower than everything else. I still thought the data was interesting, though, so I have created a graph with those values truncated as I did in the original post's followup. The one critical difference is that I am plotting the 10,000 record inserts instead of 100,000 like last time. That just took too long to run ![]()
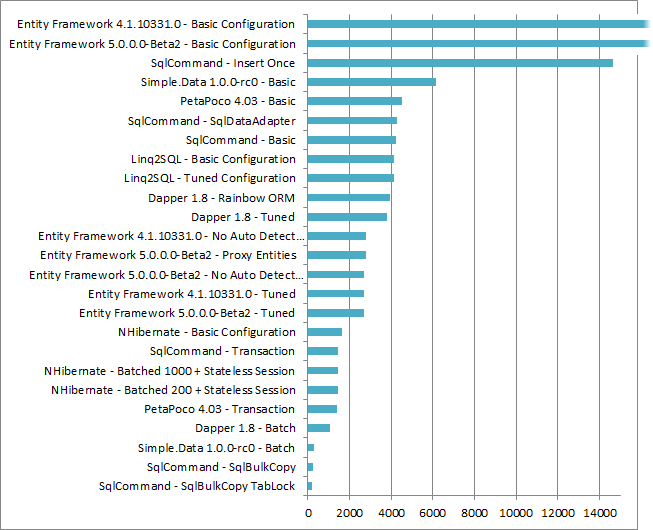
10,000 row inserts, All categories and variants
With more details we can see the spread and variation a little more clearly.
Big 'Ol String method: One of the other surprises I ran into when doing this was how slow the "cram it all into one long string" method was ("SqlCommand - Insert Once" above). This is often suggested as a quick and dirty way to do batch insertion, basically by concatenating all the data into a single long INSERT statement with multiple VALUE rows or UNIONs. At 100 records this option tied with Dapper as the fastest method. Unfortunately it scales really horribly, moving up to nearly last, leading me to believe that people suggesting this method only tested it in lower ranges.
Conclusions
In my last post I concluded that I wouldn't use an ORM for batch processing, but Simple.Data has forced me to reconsider that statement. Raw speed is not the only measure I would use to select a tool for getting data A into database B, but it is clear that if my requirements include bulk data insertion, ORMs are no longer automatically taken off the table. Congratulations to Mark for making a very clean, very fast way to get a whole lot of data into a database for very little up front effort (and thanks for adding it to my todo list).