I am working on a manufacturing simulator as part of a side-project and needed the ability to store the state of jobs and orders that would change statuses over time. In most cases, querying by the job id is sufficient, but there are occasions where I need to query by a job status field or date range.
LevelDB has been a great, lightweight addition that handles the "by key" requests wonderfully, but doesn't have indexing built in. Luckily it does include the ability to read a range of keys, so we have the basics we need to build and manage indexes from the application. If you're already an expert at indexing, or attempting to solve this at scale, this won't be the post for you. If you have a key/value store and need some lightweight indexing, this post may be useful.
This post uses the following dependencies/versions:
// ...
"engines": {
"node": ">=8.0.0"
},
"dependencies": {
"encoding-down": "^5.0.4",
"leveldown": "^4.0.1",
"levelup": "^3.1.1"
},
// ...Working source code for all of the examples is on github.
While the code in question is in javascript with LevelDB, the concepts map to many other technologies.
Setting the Stage
To set the stage, let's look at a few basic operations against leveldb using the levelup package
(levelup docs)
First, I've created an instance of levelup utilizing the encoding-down and level-down libraries:
const levelup = require('levelup');
const leveldown = require('leveldown');
const encode = require('encoding-down');
// create the data store
const db = levelup(encode(leveldown(`./data/datastore-1`), { valueEncoding: 'json' }));If you're not using javascript or unfamiliar with LevelDB, this defines a data store that will be located on my filesystem and automatically serialize/deserialize values as JSON.
Operating on the data store is pretty easy. You can put, get, and del (delete)
a single sampleObject by it's uniqueKey property:
// add the sampleOrder to the database
await db.put(sampleOrder.id, sampleOrder);
// get a copy out of the database
const retrievedVersion = await db.get(sampleOrder.id);
console.log(retrievedVersion);
// delete it from the database
await db.del(sampleOrder.id);Output from the get:
{ id: 'sample-order-1', date: 1546368617810 }In addition to basic operations, LevelDB also supports batch operations,
which are applied atomically, and the ability to read a range of
values with createReadStream.
// perform a series of puts as a batch
await db.batch([
{ type: 'put', key: 'sample-order-1', value: sampleOrder1 },
{ type: 'put', key: 'sample-order-2', value: sampleOrder2 },
{ type: 'put', key: 'sample-order-3', value: sampleOrder3 }
]);
// read the series back out
const values = await new Promise((resolve, reject) => {
const tempValues = [];
db.createReadStream({
gte: 'sample-order-1',
lte: 'sample-order-3',
keys: true,
values: true
})
.on('data', (data) => {
tempValues.push(data.value);
})
.on('error', (error) => {
reject(error);
})
.on('close', () => { })
.on('end', () => {
resolve(tempValues);
});
});
console.log(values); // outputs 3 sample ordersI've added some extra complexity around the createReadStream method
that converts the stream to a Promise'd Array.
Here is sample output for those roundtrip values:
[ { id: 'sample-order-1', date: 1546368617810 },
{ id: 'sample-order-2', date: 1546368617810 },
{ id: 'sample-order-3', date: 1546368617810 } ]Note: createReadStream supports several options to define the bounds of the search: levelup docs
Example Scenario
So here's an example scenario: We're storing sales orders in a key/value store, but realize that we're going to want to be able to show a list of all sales orders for a given range of days.
Approach #1: In-Memory Search
Our database doesn't support indexes natively, so we know we're going to have to manage this in the application. One option would be to simply read all of the records into the application and filter:
async function findByDate(db, dateStart, dateEnd) {
const values = await new Promise((resolve, reject) => {
const tempValues = [];
// 1: read all id's from 'sales-order-*' to 'sales-order.'
db.createReadStream({
gte: 'sales-order-',
lt: 'sales-order.',
keys: true,
values: true
})
.on('data', (data) => {
tempValues.push(data.value);
})
.on('error', (error) => {
reject(error);
})
.on('close', () => { })
.on('end', () => {
resolve(tempValues);
});
});
// 2: then find matches
const matchingValues = values.filter(v => v.date >= dateStart && v.date <= dateEnd);
console.log(`Loaded ${values.length} records, ${matchingValues.length} match date range ${dateStart} to ${dateEnd}`);
return matchingValues;
}This solution has some downsides. As your data increases, it's not going to scale well, as you're downloading and deserializing every record in the data store to filter. On the other hand, if you know you will have a small data store, the upside is that it is straightforward and less prone to bugs than a more complex solution.
But let's pretend we're going to have a lot more data and add some complexity.
Approach #2: Store an "Index" file
If we're not going to download every record to perform our search, then what if we maintained an index file that includes the fields we would want to search? That would allow us to download one record into memory, perform the search, and then download only the specific items we need.
To make this work, we'll need to write our own put and get logic, to ensure
that we're keeping the index up to date with every put and then using it for
our searches:
// put an item in the index when storing it
async put(item) {
// get the index
const index = await this._db.getOrDefault('sales-order:index', []);
// filter out the item if it's already here
const filteredIndex = index.filter((i) => i.id != item.id);
// add an entry
filteredIndex.push({ id: item.id, date: item.date });
// write the index + new record
await this._db.batch([
{ type: 'put', key: 'sales-order:index', value: filteredIndex },
{ type: 'put', key: item.id, value: item }
]);
}
// find things from the index
async findByDate(startDate, endDate) {
// open the index
const index = await this._db.getOrDefault('sales-order:index', []);
// search it
const matchingIndexEntries = index.filter((i) => {
return i.date >= startDate && i.date <= endDate;
});
// retrieve those items
return Promise.all(matchingIndexEntries.map((i) => {
return this._db.get(i.id);
}));
}Storing an item has gotten a little more complex. Not only are we adding an entry to the index each time, we have to account for:
- The index may not exist yet! (thus the custom
getOrDefaultmethod) - It may already be present in the index
However using this is still straight forward and we're not loading the whole dataset into memory now
// add a record
await store.put(new SalesOrder({ id: 'sales-order-123', date: today, totalAmount: 123.45 }));
recordsInStore = await store.count();
console.log(`${recordsInStore} records stored in index`);
// find a set of records
const results = await store.findByDate(twoDaysAgo, oneDayAgo);
console.log(`${results.length} records found between ${twoDaysAgo} and ${oneDayAgo}`);Unfortunately, this approach has one giant weakness: concurrency. If two users save orders at the same time, both records will be added to the store but only one copy of the index will be preserved:
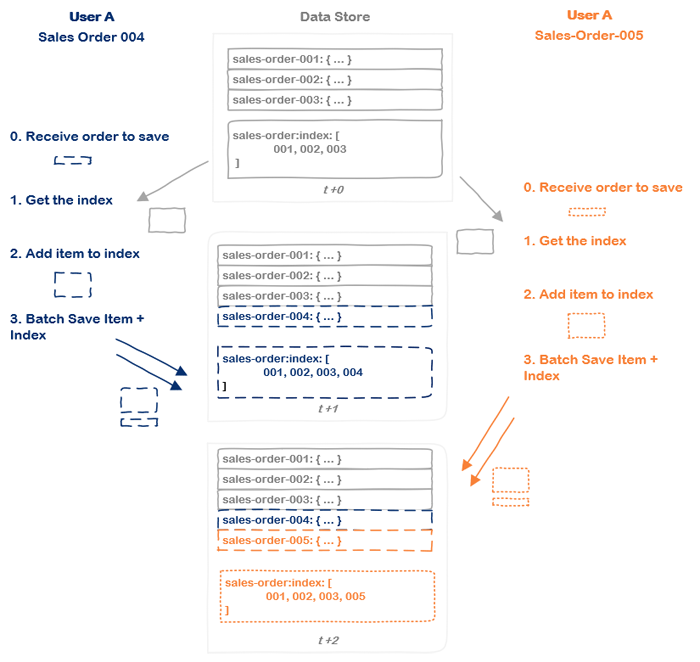
Conflict: Overwriting the Index File
So let's look at a third option.
Approach #3: Key ranges as index
As I noted in the beginning, LevelDB supports the ability to read a range of
keys using the createReadStream operation and it has an atomic batch operation.
Given those two details, than another possibility is to store the item with one key
and a second "index" key/value pair, using the indexable fields in the key name so
we can select a range of them using createReadStream:
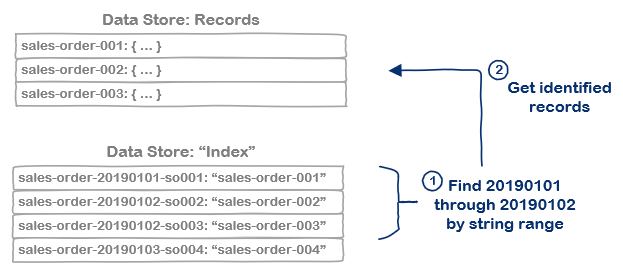
Individual 'Index' key/value pairs
Following the same structure as the prior example, we can write a put and a
findByIndex method:
async put(item) {
const getItemKey = (i) => `sales-order:${i.id}`;
const getIndexKey = (i) => `index:sales-order-by-date:${i.date}:${i.id}`;
const operations = [
// add the item
{ type: 'put', key: getItemKey(item), value: item },
// add an index entry
{ type: 'put', key: getIndexKey(item), value: getItemKey(item) }
];
// do we need to remove a prior index?
const oldItem = await this._db.getOrDefault(item.id, null);
if (oldItem != null && oldItem.date != item.date) {
operations.push({ type: 'del', key: getIndexKey(oldItem) });
}
// apply them
await this._db.batch(operations);
}
async findByDate(startDate, endDate) {
// index name prefixes
const indexStart = `index:sales-order-by-date:${startDate}`;
const indexEnd = `index:sales-order-by-date:${endDate}`;
// search the index
const index = await new Promise((resolve, reject) => {
const indexValues = [];
this._db.createReadStream({
gte: indexStart,
lt: indexEnd,
keys: true,
values: true
})
.on('data', (data) => {
indexValues.push(data.value);
})
.on('error', (error) => {
reject(error);
})
.on('close', () => { })
.on('end', () => {
resolve(indexValues);
});
});
// return the individual records
return Promise.all(index.map(key => this._db.get(key)));
}We so still keep the win from the prior solution, only requesting the subset of the data store we care about, but now two users can simultaneously put records in without disrupting each other. There is a concurrency problem if two users edit the same exact record simultaneously, but it results in an item having 2 indexes pointing to it, rather than being left out, leaving you with options you don't have in the prior method.
Wrapping Up
These are 3 relatively light approaches to adding indexing to a key/value store and
they all have narrow cases they will work for, with large holes when used for others.
If your system supports locks or transactions (or you add in a index:lock... key +
logic), you can expand this even further. So my advice would be to always start
with option #1 if you don't have a built-in option, and avoid option 2 even if you
have locking.